Note
LLM
AI
FeatureSpotlight
Twitterでしか扱っていなかったLLMの話題ですが、記事に残す価値がありそうなネタをたまたま発見したのでメモ程度に。
> EXL2とは
turboderp氏によるExLlamaV2という"最新のコンシューマ GPU でローカル LLM を実行するための推論ライブラリ"に追加されたGPTQ派生の量子化モデルの事
GPTQ-for-LLaMAのパフォーマンス向上を目指したExLlamaの新バージョンに当たるのがExLlamaV2のようだが、このV2バージョンから新たにGPTQとは異なる新たな独自量子化規格(名称からして恐らく)が提唱された。それがEXL2である。
> GPTQとの違いについて
解説記事を読んだ限りで最も把握しやすい例が載っていたのはこちらの記事(中国サイトにつき注意)
この記事と実際の変換処理で把握できた事を踏まえて要約すると
GPTQの場合は4bit -> 3bitへすべてのレイヤーを一定bitへ量子化するのに対して、EXL2は量子化を行う前の段階で1レイヤー毎に約2.0~8.0bit範囲で量子化した場合に発生するエラーレート(rfn_error)を測定用データセットを元にベンチマークを実行し、その中で最も結果が良好(エラーレートが低い)かつモデルの重要なレイヤーを厳選してより高い精度で量子化するという工夫が施されているらしい。
平たく言えば
モデルの中身に応じて精度を高くする部分と低くする部分を動的に調整したモデルが出力出来る = すべてのレイヤーを単純に3bitへ量子化するGPTQよりも高精度な量子化・VRAM 24GBでも単純にGPTQ 2~3bit変換するよりもVRAM消費を抑え、精度をなるべく維持した量子化が可能
といった所か。
(EXL2は動画エンコード設定でお馴染みのCBR / VBRのうちVBRに近い形式で量子化すると言えばわかりやすいかもしれない)
> EXL2量子化の方法について(Win/非WSL)
筆者は一応WSL2・Winネイティブ・Mac・Linuxと幅広く扱えるが、RTX 4090が積まれているのはWin環境かつ今回はtext-generation-webuiにささっと量子化モデルをインポートして使えるようにしたかったのでWinネイティブで既存モデルをEXL2化する手法を記す。
準備するもの
+ RTX 4090 or VRAM 24.0GB GPU
これが無ければなにも始められません。ご家庭でA100等といったような論外な環境を要求しているわけでは無いので準備しましょう。(円安ぇ)
+ DRAM 64GB前後
量子化時や推論時のパフォーマンスを観る限りではVRAMだけではなくDRAMも最低でも64GB以上はあった方が良いでしょう。ただGGUFとは異なりEXL2はGPTQと同様にGPUに依存する事になるのでそこまで重視する必要はないはず。
+ text-generation-webui
text-generation-webuiは記事執筆時点の最新バージョンでExLlamaV2による推論を標準サポートしてくれているのとポータブルconda環境に"cmd_windows.bat"経由で簡単にアクセス出来るようになっているので1から環境構築するよりも圧倒的に素早く量子化プロセスを始められるので活用すべきでしょう。
+ 70B LLMモデル(オリジナル/非量子化)
EXL2は制作者の検証リストに"Llama2,TinyLlama,CodeLlama"の記録があるようなのでこれらのモデルから派生したモデルまでは恐らくEXL2量子化が可能と見て良いでしょう。
+ 量子化bit最適化パターン測定時に使用するデータセット
EXL2への変換プロセスを行う際に使用される最適化を行う為の精度を測定する際に使用するデータセットが必要です。形式はjsonではなくparquetが必要。これについては基本的には量子化したいモデル学習時に使用されたデータセットのparquetを食わせれば問題ないはず。
>>今回の記録で量子化する例
+ 70B LLMモデル: stabilityai/japanese-stablelm-instruct-beta-70b
+ 量子化bit最適化パターン測定時に使用するデータセット
japanese-stablelm-instruct-beta-70bは3つのデータセットが主に組み込まれていましたが、筆者の場合は対話・アシスタントを重視したかったのでこちらを選択しました。
> 量子化手順
1: text-generation-webuiセットアップ
省略。ExLlamaV2がサポートされているバージョンが必要なので古い場合は再構築した方がいい。
2: cmd_windows.bat起動 & git clone ExLlamaV2
前述していた通り、Winネイティブで1からセットアップするよりもtext-generation-webuiのセットアップ済みのconda環境を利用して無駄な手順を省く。まずはcmd_windows.batを叩き起こしてからExLlamaV2をcloneしてくる。
3: 70Bモデルダウンロード & データセット準備
download-model.pyを使用するかWebUI上で任意の70Bモデルをダウンロードしておく。データセットは後の手順でパスを指定することになるので任意のディレクトリにHuggingFaceの"Auto-converted to Parquet"からParquet形式でデータセットをもってくるといい。
4: 必須要件インストール(必須ではない手順)
多分この手順は不用と思われるが念のため。exllamav2ディレクトリに移動する前にpip install exllamav2で必須要件が不足していないかどうかを確認する意味でも一度実行しておくと良いかもしれない。
5: exllamav2ディレクトリへ移動・変換実行
オプション情報はドキュメントを観るべき。
必須オプションのみ解説。
・-i = オリジナルモデルのディレクトリを指定
・-o = 中間ファイルの出力先。これが変換済みのモデルが収められるディレクトリではない。
・-c = 量子化bit最適化パターン測定時に使用するデータセットを指定する。
・-cf = 変換完了後のモデルデータが収められるディレクトリを指定。
・-b = 量子化する際のターゲットbitを指定する。ここで指定したbitを基準に前述した測定+レイヤーに適応する量子bitが決定される。ドキュメントにもあるように70BかつVRAM 24GBに収まるようにする場合は2.5よりも下の値を指定する事になる。
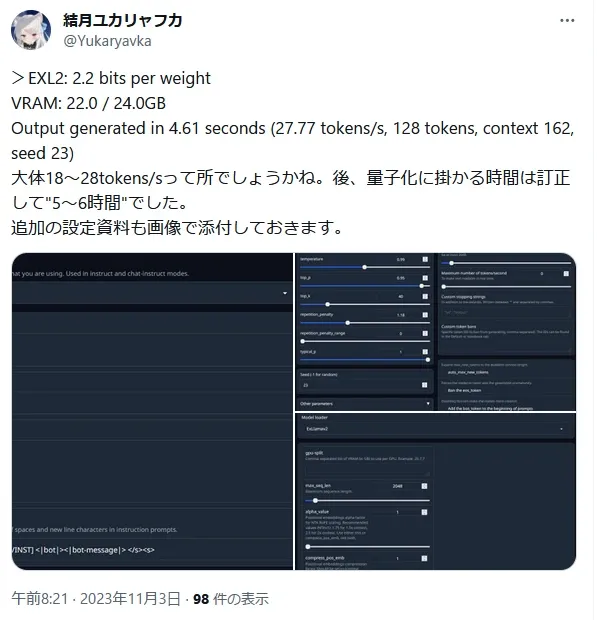
※stabilityai_japanese-stablelm-instruct-beta-70bの場合、2.5bitではモデルロード時点で"23.5/24.0 GB"と推論の余裕が無く、数文字出力した時点で出力が止まってしまったので2.2bit前後を基準にすると良い。
> 変換コマンド例
後は量子化が終わるのを待つだけ。stabilityai_japanese-stablelm-instruct-beta-70bでこちらの環境では1回の量子化処理完了までに5~6時間掛かったので注意。
・量子化実行中のパフォーマンスメモ
CPU: 12~16%
GPU: 82~100%
DRAM: 7415.00 MB
VRAM: 13.3GB / 24.0 GB ~ 17.6 / 24.0 GB
> 性能チェック等
今のLLM業界では定量評価といった情報が溢れているのでより詳細な検証をしたい方はご自身でどうぞ。
(もっと安定した結果が出せるようなら評価してみても良いかもしれない)
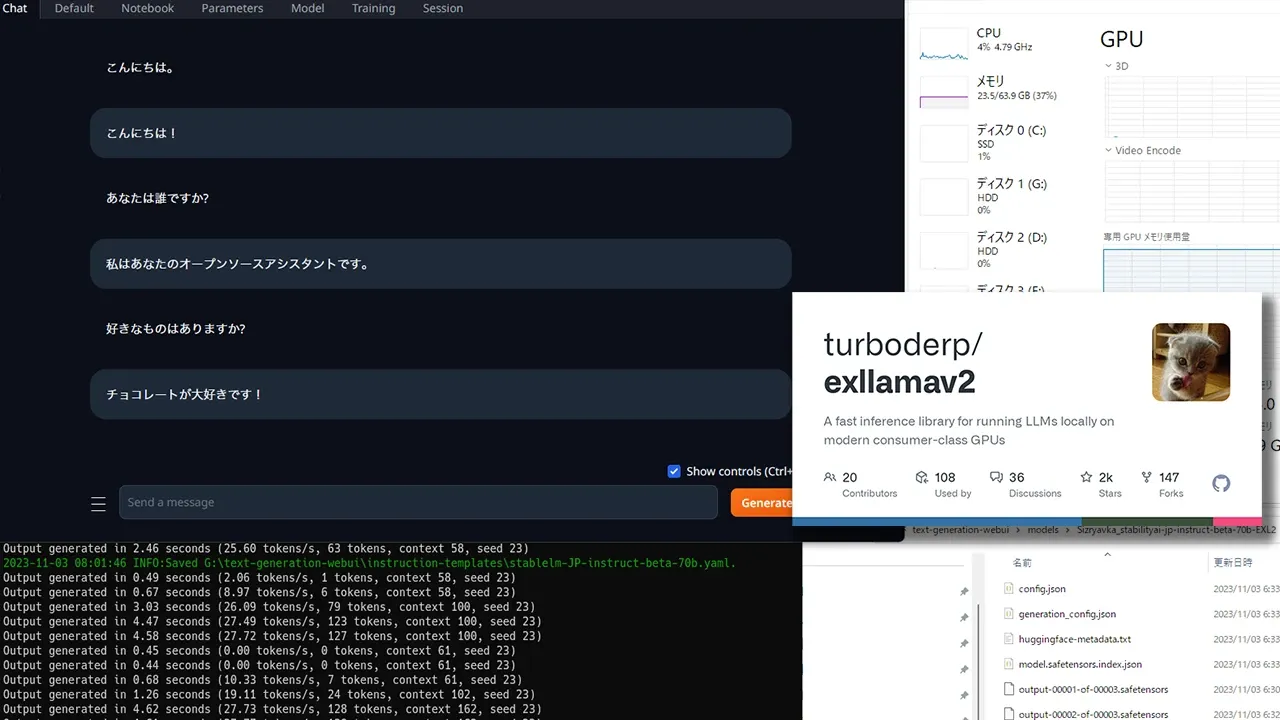
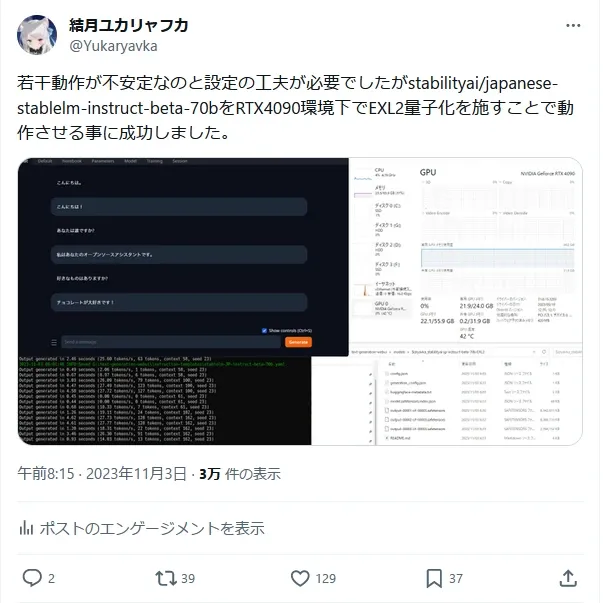
> 動作報告
・初回成功 - 2.2bit 報告ツイ
> 2.2bitモデルの問題点
動作が不安定な点。必ずしも1回のGenerateで良好な結果を得られない場合がある。報告用の画像で挙げたものだと2~3回Regenerateして結果を引き出せてるので、もう少しターゲットbitを引き上げてロスを防ぐか、設定をより詰めれば少しだけでもマシにはなるかもしれない。
> 出力NG例
実際のNG出力例(原文ママ)をいくつか記録する。
※以下の記録は 2.4bitモデルのNG出力例
・Case1: 出力が不安定な例。回答も劣化しているが、応答にはなっている。
User: こんにちは。
AI: こんにちは、私はAI言語モデルです。どのように私が助けることができますか? <inst
User: まず、あなたは何のお手伝いが出来るのですか?
AI: 回答…もしやむことがあります…コードを書く …オープンソースを介した調整を伴う…音楽を作成し…物事を上書きする…
・Case2: 最初の書き出しのみを見れば悪くないが、文章が続かず崩壊する例
User: あなたは今何を考えていますか?
AI: 私はとても単純なコンピュータープログラムに過ぎりません。実際、最初のセッションが言うことがあるというのが少し良好です。おやすされ、ある場合など、自分で判断しようとしてください。[オープンアシスタントの開発チームから、「人間」と同��
これらのNG例も含めて観る限りでは、会話に影響を及ぼす程のデータ損失があるのは間違いなく、今すぐに実用的に使えるといった事はまず無いだろう。最も、EXL2も記事を書いた時点ではこの規格が登場してから2ヶ月前後であり、これからが期待されるプロジェクトである段階と観るべきだろう。